Side-Channel Vulnerabilities in Wearable & Extended Reality Devices
This research investigates how immersive computing systems unintentionally expose private user information through passive side channels that arise from the way wearable, virtual reality, augmented reality, and mixed reality devices render, mediate, and externalize user interaction. Instead of treating privacy leakage as a result of device compromise, malware, or direct sensor access, this work studies the broader attack surface created by observable signals in shared physical and virtual spaces, including body motion, avatar animation, display behavior, and optical artifacts. The research develops realistic adversary models and end-to-end inference pipelines that combine data collection, signal preprocessing, computer vision, and domain-adapted machine learning to recover sensitive information from noisy, indirect observations. Across immersive environments, these signals can reveal private inputs, authentication behavior, spoken content, application context, and on-screen information, even when the adversary has no privileged access to the device or platform. This line of work spans IRB-approved human-subject studies, synthetic and real-world dataset construction, and evaluations across commercial AR, VR, and MR platforms to characterize how physical, visual, behavioral, and perceptual design choices can become privacy leakage channels. By identifying these risks as systemic properties of immersive interaction rather than isolated vulnerabilities, this research aims to guide the design of architectural, software-level, and user-interface defenses that reduce information exposure while preserving usability, realism, and social presence in future immersive systems.
Ongoing Research
Inferring Speech from Lip Motion in Social VR Avtars

Two avatars conversing in the Immersed VR platform. A passive adversary co-present in the shared virtual room can observe avatar lip motion from a standard co-worker distance, recording speech content without access to audio or platform internals.
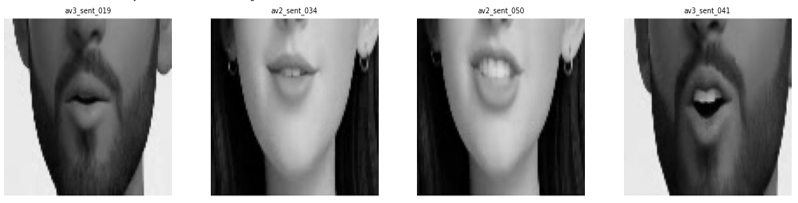
Extracted 96x96 grayscale mouth region of interest (ROI) patches from six AI-generated avatars in the synthetic dataset. These crops serve as input to the fine-tuned AV-HuBERT visual speech recognition model across diverse facial geometries and skin tones.
Social Virtual Reality (VR) platforms increasingly rely on expressive avatar facial animation to enhance presence and communication. While these features improve user experience, they may unintentionally expose sensitive information through visual side channels. This project investigates whether avatar lip motion in multi-user VR environments constitutes a viable side channel for inferring spoken speech content. We propose a passive visual adversary model in which an attacker observes only the rendered lip movements of a target avatar, without access to audio, internal telemetry, or network traffic. We construct a synthetic dataset of 402 avatar videos across six AI-generated avatars speaking 17 passages and 50 phonetically optimized sentences, and fine-tune AV-HuBERT, a self-supervised audio-visual speech recognition model, on video-only input.
The steps involved in the end-to-end avatar lip-motion inference pipeline follow.
- Synthetic Dataset Construction (6 AI avatars, 402 videos, 17 passages + 50 sentences)
- VR Data Collection via Passive Screen Capture in the Immersed Platform
- Face Detection and Mouth ROI Extraction (MediaPipe, 96x96 grayscale patch)
- Temporal Stabilization and Landmark Smoothing
- Fine-Tuned AV-HuBERT Visual Speech Recognition (video-only, audio masked)
- Evaluation under Three Conditions: Unseen Avatar, Unseen Content, Real VR Speakers
LightLeaks: Optical Leaks on Mixed Reality Waveguide Displays
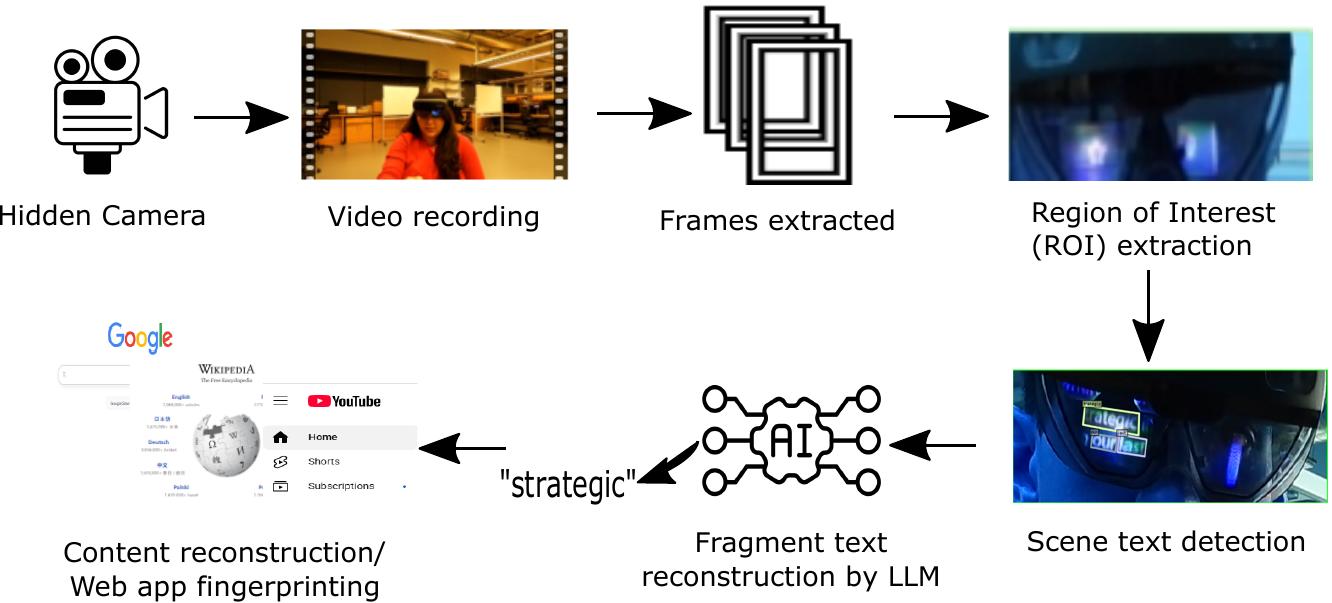
Overall LightLeaks attack pipeline. Video captured by a hidden camera observing optical leakage from a waveguide-based MR headset is decomposed into frames, filtered to isolate the display ROI, and scene text is reconstructed using LLM-based inference to recover sensitive content fragments.

Content inference examples from leaked UI fragments: Google logo, email content words, Wikipedia URL fragment, and Amazon shipping terms — all recovered passively from waveguide optical leakage.
Optical see-through (OST) mixed reality glasses, such as the Microsoft HoloLens 2, Magic Leap 2, and Snap Spectacles, use transparent waveguide-based near-eye displays that project virtual imagery into the wearer's field of view. LightLeaks identifies and exploits an inherent physical side channel of this architecture: light unintentionally leaking outward from the waveguide during normal operation. A passive bystander equipped with only a consumer camera, positioned at approximately 1 meter under ambient indoor lighting, can capture these optical emissions and recover private on-screen content, identify active applications, and infer authentication inputs, all without device compromise, malware, or specialized equipment. This vulnerability is architectural and affects the entire class of diffractive waveguide-based AR/MR displays.
The steps involved in the end-to-end LightLeaks attack pipeline follow.
- Video Capture via Consumer Camera (~1 m standoff)
- Facial Landmark-Based Region of Interest (ROI) Extraction
- Domain-Adapted Scene Text Detection (ESTextSpotter, fine-tuned on waveguide imagery)
- Fragment-Aware LLM Reconstruction (temporal voting, cross-frame stitching, noise rejection)
- Content Recovery, Application Fingerprinting, and Credential Inference
HiddenReality: Video-based Leaks in Wearable (VR) Devices

Attacker's view of a target user's typing from a distance.
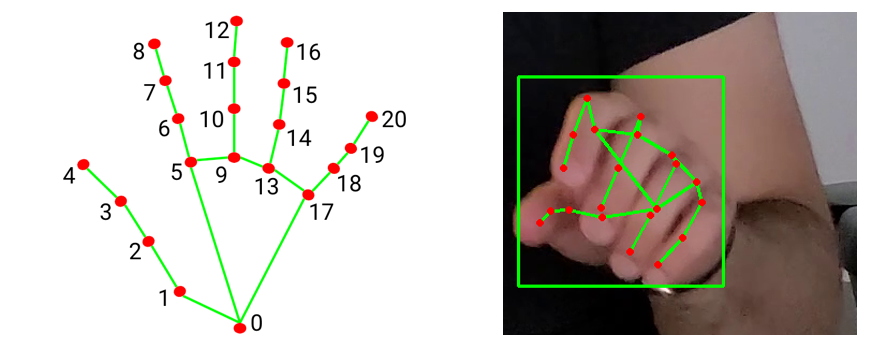
Landmark points detected on the user's hand while they type.
A video-based side-channel attack, Hidden Reality (HR), shows although the virtual screen in VR devices is not in direct sight of adversaries, the indirect observations such as hand gestures might get exploited to steal the user's private information. The Hidden Reality model can successfully decipher an average of over 75% of the text inputs.
The steps involved in the implementation of the Hidden Reality attack model for various attack scenarios follow.
- Video Preprocessing
- Localization and Hand Landmark Tracking
- Click Detection
- Character Inference
- Word Prediction
Datasets
This research uses a combination of real-world and synthetic data collection to study privacy and security risks in AR/VR and mixed-reality environments. All human-subject data collection was conducted with university IRB approval and involved registered volunteer participants performing realistic interaction tasks across multiple immersive platforms.
For the Meta Quest 2 study, videos were recorded while participants entered information on a virtual screen. A total of 368 short video clips were collected across several attack scenarios, including password entry, PIN entry, graphical-lock pattern entry, text entry, and email entry.
For the Microsoft HoloLens 2 study, 10 volunteer participants were recorded from a 1-meter distance using a Nikon Coolpix P950 camera and an iPhone SE. Participants performed naturalistic tasks such as email reading, web browsing on platforms including Google, Wikipedia, YouTube, and Amazon, as well as credential entry involving PINs and passwords. A preliminary evaluation was also conducted on the Magic Leap 2 from a 3-meter standoff distance to assess generalizability across waveguide-based mixed-reality platforms.
To complement the real-world recordings, a synthetic dataset of 402 videos was generated using HeyGen, a commercial AI avatar generation platform. The dataset included six avatars with variation in facial geometry, skin tone, and lip shape. Additional real-world VR data was collected from five participants in the Immersed platform, recorded from an adversarial viewpoint at approximately 1–2 meters in a shared virtual meeting room. Participants spoke a novel passage not included in synthetic training, enabling a fully out-of-distribution evaluation.